Scalability is one of the defactos for modern web applications, especially in distributed high throughput systems. But there is a lot of misconception around the primary objective of a scalable application. Scale is not just about designing Web sites that don’t crash when lots of users show up. It is about designing your company so that it doesn’t crash when your business needs to grow.
The book, The Art of Scalability, describes a really useful, three dimension scalability model: the scale cube. This cube defines the three main ways to achieve the maximum scalability for an application.

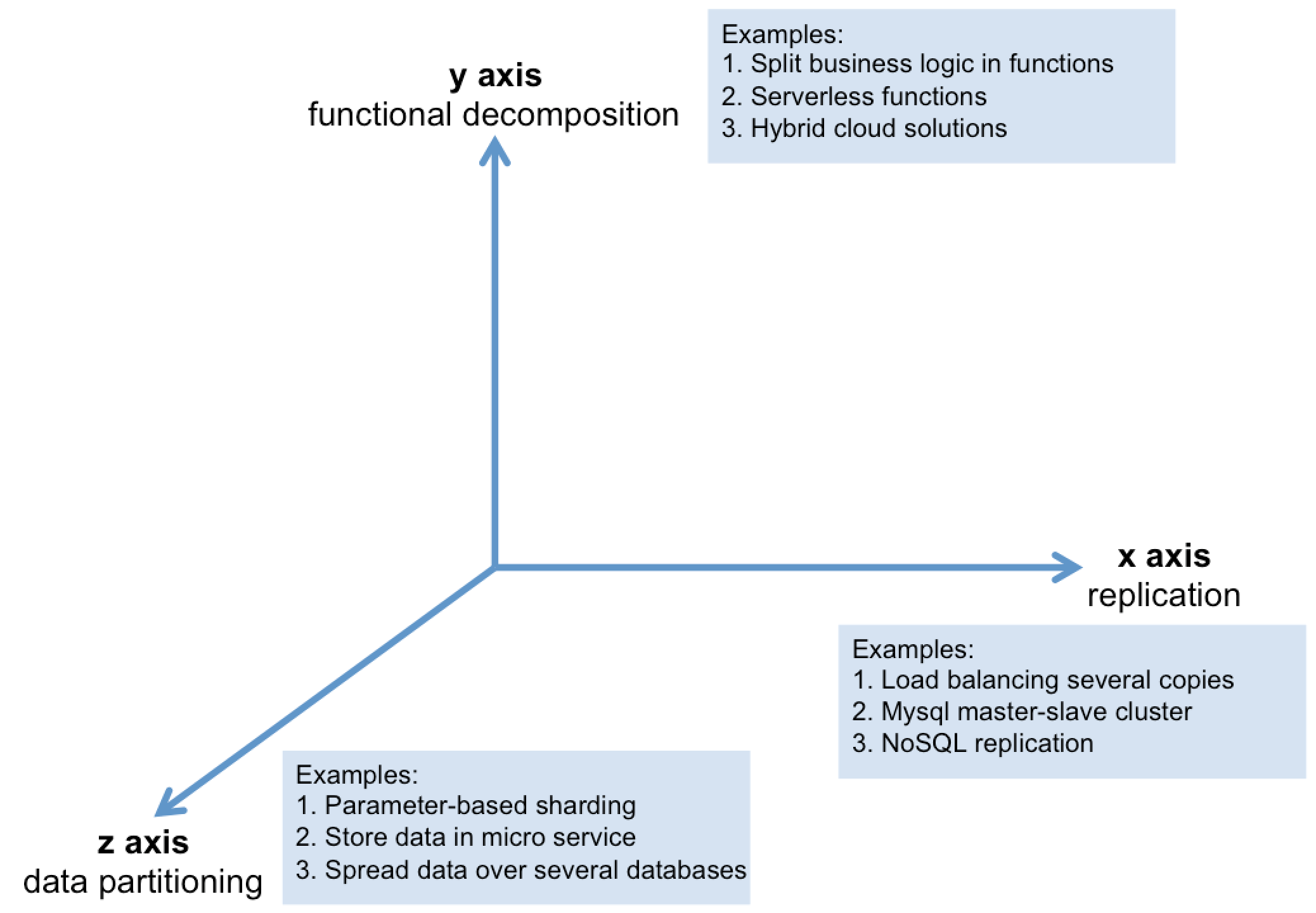
X-axis scaling
- This is a simple, commonly used approach of scaling an application.
- Running multiple copies of an application behind a load balancer. If there are N copies then each copy handles on average 1/N of the load.
Drawbacks
- Each copy potentially accesses all of the data, caches require more memory to be effective.
Y-axis scaling
- Splits the application into multiple, different services where each service is responsible for one or more closely related functions.
- Microservice based architecture is a common area of Y-axis scaling.
- The most common way to decompose the application into functional services is to use the idea of Bounded Context in Domain Driven Design (DDD)
Drawbacks
- Increase the complexity of common service behaviors like monitoring, logging, authentication.
- Tricky on handling the inter-service communications.
Z-axis scaling
- Scaling through partition the data where each server runs an identical copy of the code. In this respect, it’s similar to X-axis scaling. But the big difference is that each server is responsible for only a subset of the data.
- Some component of the system is responsible for routing each request to the appropriate server.
- Commonly used to scale databases. Data is partitioned (a.k.a. sharded) across a set of servers based on an attribute of each record.
- A router sends each content item to the appropriate partition, where it is indexed and stored. A query aggregator sends each query to all of the partitions and combines the results from each of them.
Benefits
- Each server only deals with a subset of the data.
- This improves cache utilization and reduces memory usage and I/O traffic.
- It also improves transaction scalability since requests are typically distributed across multiple servers.
- Also, Z-axis scaling improves fault isolation since a failure only makes part of the data inaccessible.
Drawbacks
- Increase the overall application complexity.
- Need to implement a partitioning scheme, which can be tricky especially if we ever need to repartition the data.


Leave a comment